RAG — intelligence documentaire¶
Service de retrieval d'AKKO. Les clients uploadent des documents dans des collections ; le service extrait le texte, le chunk, calcule les embeddings 768 dim via la passerelle AI souveraine, et stocke le tout dans un vector store dans la couche Storage de la plateforme. Les appelants (ADEN, cockpit, agent, notebook) posent ensuite des questions en langage naturel sur une collection et reçoivent des chunks classés avec la provenance complète.
Phase 0 — tier 1 seulement
Le service est prévu pour grandir en trois phases derrière le même contrat. Phase 0 (livrée) : un vector store embarqué pour des collections jusqu'à ~1 k documents. Phases 2-3 : recherche hybride et backend big-data, sans casser aucun appelant. Plan complet : rag-document-intelligence.
Architecture¶
flowchart LR
subgraph Clients
CK[Cockpit /#rag]
ADEN[ADEN]
NB[Notebook]
AG[Agent]
end
subgraph RAG["akko-rag (FastAPI)"]
API[/collections<br/>/documents<br/>/query/]
EX[Extractor<br/>pypdf / txt / md]
CHK[Chunker<br/>fenêtre de mots]
EMB[Embedder<br/>retry 3x]
end
subgraph Backends
PG[(akko-postgresql-data<br/>schéma akko_rag<br/>pgvector HNSW + GIN)]
LL[akko-litellm<br/>embed + chat]
end
Clients --> API
API --> EX --> CHK --> EMB --> LL
EMB --> PG
API <--> PG
Formats supportés¶
Le pipeline d'ingestion extrait le texte avec pypdf pour les PDF et un
lecteur UTF-8 pour les formats textuels. Les formats sont validés sur
l'extracteur réel (docker/akko-rag/app/extractor.py), sans promesse
marketing :
| Format | Extension / MIME | État | Notes |
|---|---|---|---|
.pdf / application/pdf |
✅ supporté | couche texte via pypdf (pas encore d'OCR) |
|
| Markdown | .md, .markdown |
✅ supporté | |
| Texte brut | .txt, .log, .csv |
✅ supporté | UTF-8 |
| DOCX | .docx |
✅ supporté | paragraphes + tableaux via python-docx |
| PPTX | .pptx |
✅ supporté | texte + tableaux par diapo via python-pptx |
| XLSX | .xlsx |
✅ supporté | valeurs de cellules par feuille via openpyxl |
| HTML | .html, .htm |
✅ supporté | balises retirées, scripts/styles supprimés (parseur stdlib) |
| Autre texte | tout text/* |
✅ au mieux | UTF-8 |
| PDF scanné | .pdf (sans couche texte) |
✅ supporté | fallback OCR à la demande via tesseract (les PDF numériques ne le paient jamais) |
| Images | .png, .jpg, .tiff |
✅ supporté | OCR via tesseract (fra+eng) ; gouverné par AKKO_RAG_OCR_ENABLED |
| Binaire inconnu | .doc, .ppt, .xls, .zip |
❌ rejeté | renvoie 400 au lieu d'indexer du mojibake |
| Audio / voix | .wav, .mp3 |
❌ non supporté | pas de transcription dans akko-rag ; un palier document scanné / voix est un item futur |
La voix n'est pas ingérable aujourd'hui
akko-rag n'a aucun chemin de transcription audio. Une note vocale doit
d'abord être transcrite en texte (par un outil séparé) avant d'être
téléversée. C'est documenté honnêtement plutôt que sous-entendu.
Guide pas à pas (depuis le cockpit)¶
Des fichiers d'exemple sont fournis dans docs/docs/assets/rag-samples/ — un
PDF, une note de politique en Markdown et un compte-rendu de réunion en texte
libre, tous fictifs et non sensibles. Utilisez-les pour reproduire ce parcours.
-
Ouvrir la page RAG. Connectez-vous en SSO et ouvrez le cockpit, puis allez dans IA & Agents → RAG (route
#rag). Vous arrivez sur RAG · intelligence documentaire.
-
Créer une collection. Cliquez sur + Nouvelle, donnez un nom (le slug est dérivé automatiquement), une description facultative, et les rôles autorisés à la lire. Laissez les rôles vides pour une collection ouverte, ou restreignez — par ex.
akko-admin— pour appliquer le contrôle d'accès.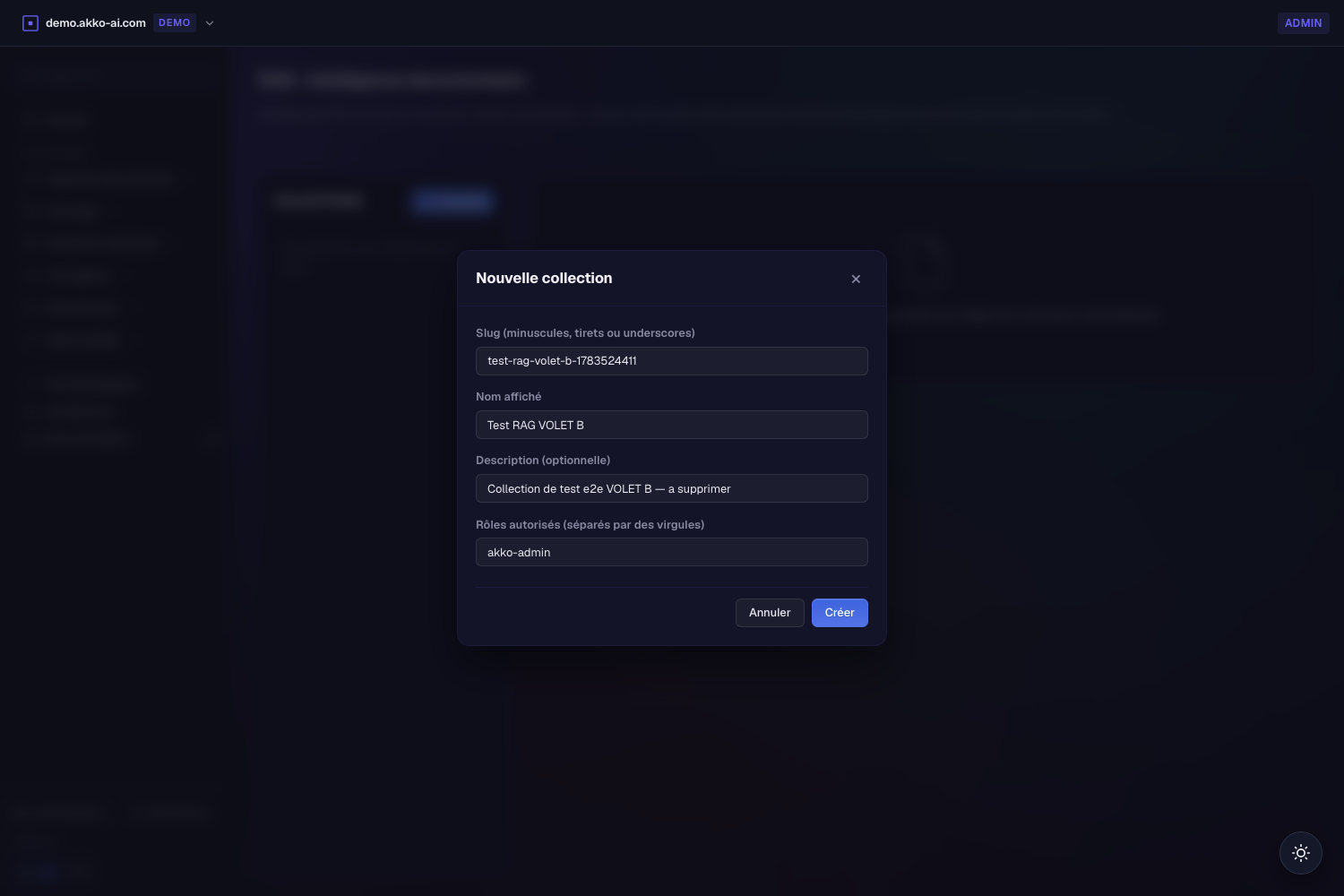
-
Téléverser des documents. Déposez les fichiers sur la zone ou cliquez pour parcourir (PDF, MD, TXT, CSV — jusqu'à 50 Mio chacun). Chaque fichier est extrait, découpé, vectorisé (768 dimensions) puis stocké. La ligne du document passe à INDEXED avec son nombre de fragments.
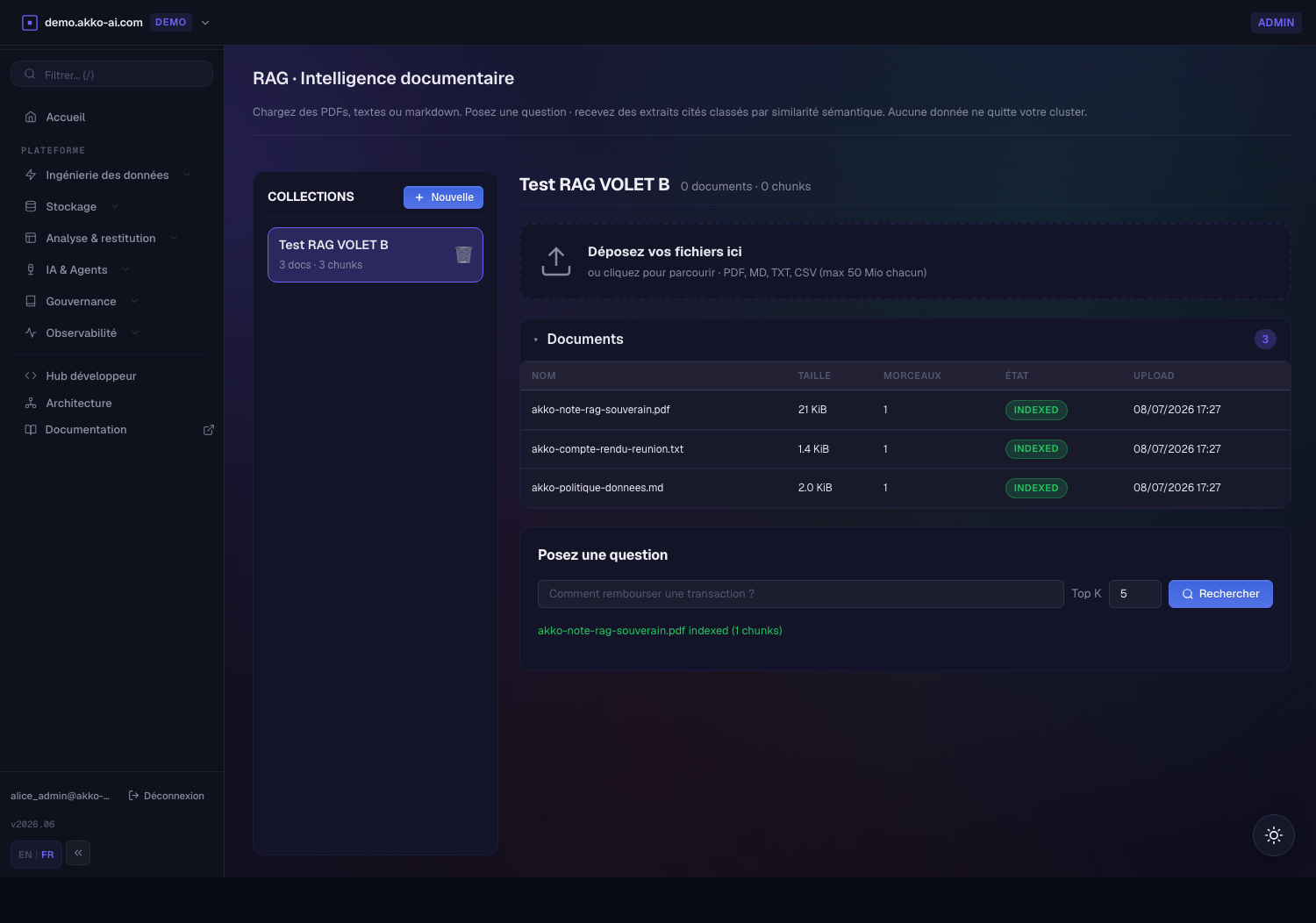
-
Poser une question. Saisissez une question en langage naturel et appuyez sur Rechercher. Le service vectorise la question, effectue une recherche par similarité cosinus et renvoie les fragments top-k — chacun avec son fichier source, sa page/section et un score de similarité. C'est la citation : chaque réponse remonte au document et au passage exacts.
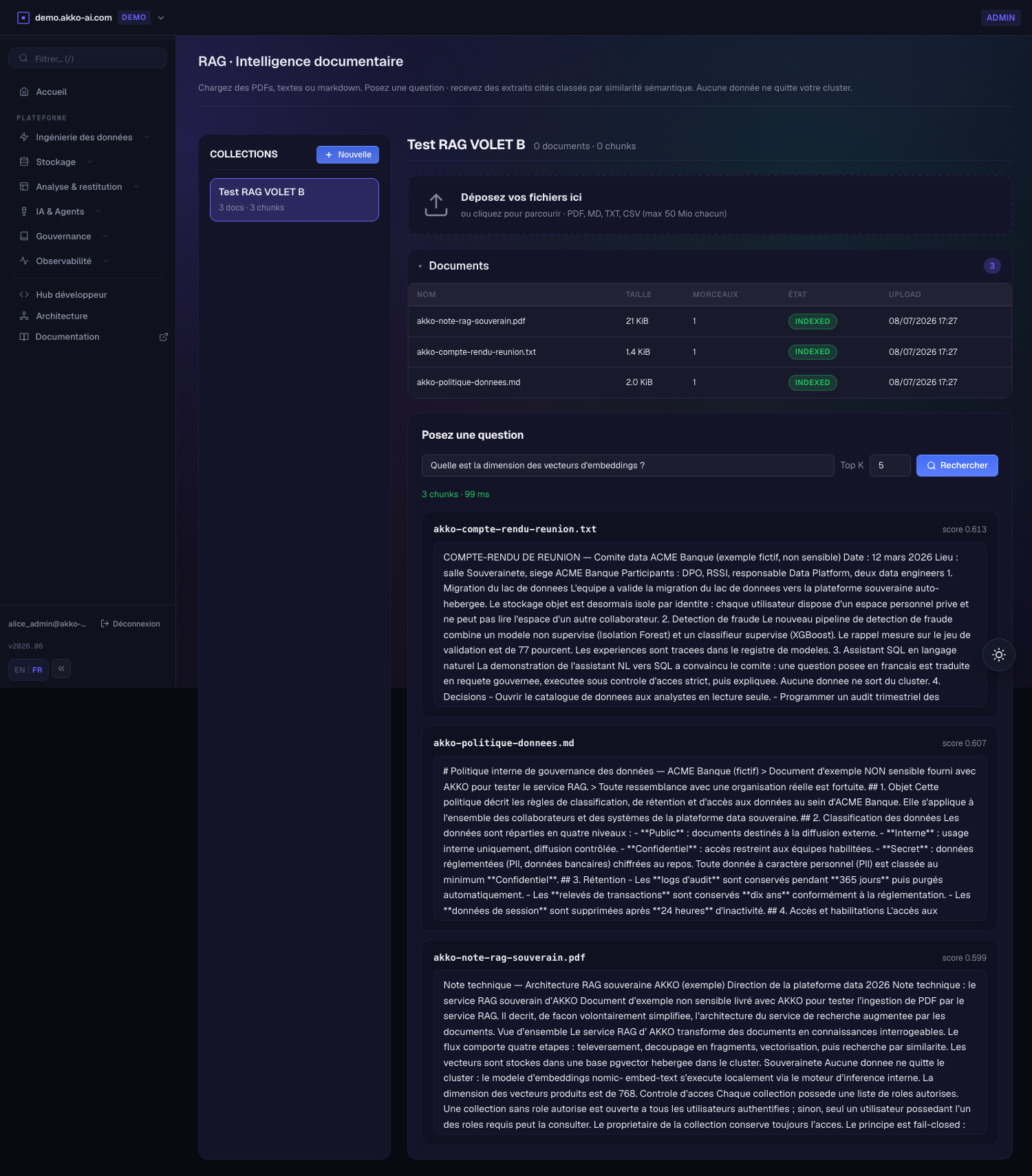
-
Gérer les accès. Un utilisateur dont le rôle plateforme n'est pas dans les
allowed_rolesde la collection ne la voit pas, ne peut pas la lister et se voit refuser (403) toute requête directe — vérifié en live aveceve_viewersur une collection réservée àakko-admin. La porte est fail-closed.
-
Supprimer la collection une fois terminé — la cascade retire ses documents et fragments. (Dans le parcours ci-dessus, tout le cycle est créé puis démonté sans toucher à aucune collection de démonstration.)
API (Phase 0)¶
| Méthode | Chemin | Rôle |
|---|---|---|
| GET | /health |
liveness |
| GET | /ready |
joignabilité de la base |
| GET | /metrics |
compteurs + histogramme Couche Métriques (Prometheus) |
| POST | /collections |
créer une collection avec allowed_roles |
| GET | /collections |
lister (avec compte documents + chunks) |
| POST | /collections/{slug}/documents |
upload → extract → chunk → embed → store |
| GET | /collections/{slug}/documents |
lister les documents |
| POST | /collections/{slug}/query |
recherche top-k par similarité cosinus |
| GET | /audit/queries?limit=N |
retrieval récents (trace d'audit) |
Identité : confiance dans l'en-tête X-Trino-User (fallback
X-User-Id) — même convention qu'ADEN et le plugin Trino AI. Phase 1
remplace par la vérification JWT Identité (Keycloak).
Exemple¶
# 1. créer une collection
curl -s -X POST https://rag.akko-ai.com/collections \
-H "X-Trino-User: alice" -H "Content-Type: application/json" \
-d '{"slug":"kb","name":"Base de connaissances",
"allowed_roles":["akko-admin","akko-engineer"]}'
# 2. uploader un PDF
curl -s -X POST https://rag.akko-ai.com/collections/kb/documents \
-H "X-Trino-User: alice" \
-F "file=@/chemin/vers/politique.pdf"
# 3. interroger
curl -s -X POST https://rag.akko-ai.com/collections/kb/query \
-H "X-Trino-User: alice" -H "Content-Type: application/json" \
-d '{"question":"comment rembourser une transaction ?","top_k":5}'
Réponse :
{
"question": "comment rembourser une transaction ?",
"collection": "kb",
"chunks": [
{
"chunk_id": "…",
"document_id": "…",
"filename": "politique.pdf",
"page": 4,
"text": "Les remboursements sont émis sous 14 jours …",
"score": 0.87
}
],
"latency_ms": 38
}
Configuration¶
Chaque paramètre se résout depuis AKKO_<NAME> ou <NAME>, pour que
values-dev, values-netcup et les runs docker locaux partagent les mêmes
défauts. Liste complète :
| Variable | Défaut | Rôle |
|---|---|---|
AKKO_PG_HOST |
akko-postgresql-data |
Hôte PostgreSQL |
AKKO_PG_PORT |
5432 |
|
AKKO_PG_DATABASE |
akko |
|
AKKO_PG_USER |
akko |
|
AKKO_PG_PASSWORD |
(Secret) | depuis Secret akko-postgresql-data |
AKKO_EMBED_URL |
http://akko-akko-litellm:4000 |
Passerelle IA (LiteLLM) OpenAI-compat |
AKKO_EMBED_MODEL |
akko-embed |
alias de routage Passerelle IA |
AKKO_EMBED_DIM |
768 |
correspond à nomic-embed-text |
AKKO_CHAT_URL |
http://akko-akko-litellm:4000 |
génération réponse Phase 1 |
AKKO_CHAT_MODEL |
akko-chat |
Phase 1 |
AKKO_CHUNK_SIZE_TOKENS |
400 |
fenêtre en mots |
AKKO_CHUNK_OVERLAP_TOKENS |
60 |
recouvrement |
AKKO_MAX_UPLOAD_BYTES |
52428800 |
plafond 50 Mio |
AKKO_DEFAULT_TOP_K |
5 |
top-k par défaut |
AKKO_MAX_TOP_K |
50 |
plafond dur |
Activer le service¶
Désactivé par défaut dans l'umbrella chart. On l'active :
Le schéma est provisionné par postgres/init/11-akko-rag.sql au
premier boot d'akko-postgresql-data. Sur un cluster déjà initialisé,
ré-appliquer le fichier à la main contre akko-postgresql-data :
kubectl -n akko exec deploy/akko-akko-postgresql-data -- \
psql -U akko -d akko -f /docker-entrypoint-initdb.d/11-akko-rag.sql
Phases à venir¶
| Phase | Livre | Backend |
|---|---|---|
| 0 (livrée) | Ingest + chunk + embed + top-k pgvector | pgvector HNSW |
| 1 | Réponse chat avec citations, auth JWT, UI cockpit, filtrage Moteur de politiques (OPA) | pgvector |
| 2 | Recherche hybride BM25 + dense, DAG watchfolder, HPA, ServiceMonitor | OpenSearch knn |
| 3 | UDF embed Moteur de calcul (Spark), colonne VECTOR Iceberg, SQL hybride Moteur de requête (Trino) | Moteur de calcul + Iceberg |
Voir aussi¶
- Architecture / Données unifiées + IA
- IA / Fonctions Trino AI —
akko_ai_searchcouvre le retrieval intra-catalogue ;akko-ragcouvre le retrieval documentaire avec citations et audit - Services / AI Service — service frère pour la génération texte/multimodale